मेमोरी ऑर्डरिंग
This article has multiple issues. Please help improve it or discuss these issues on the talk page. (Learn how and when to remove these template messages)
(Learn how and when to remove this template message)
|
मेमोरी ऑर्डरिंग सीपीयू द्वारा कंप्यूटर मेमोरी तक पहुंच के क्रम का वर्णन करता है। यह शब्द या तो संकलन समय के दौरान संकलक द्वारा उत्पन्न मेमोरी ऑर्डरिंग को संदर्भित कर सकता है, या रन टाइम (प्रोग्राम जीवनचक्र चरण) के दौरान सीपीयू द्वारा उत्पन्न मेमोरी ऑर्डरिंग को संदर्भित कर सकता है।
आधुनिक माइक्रोप्रोसेसरों में, मेमोरी ऑर्डरिंग सीपीयू की मेमोरी ऑपरेशंस को फिर से व्यवस्थित करने की क्षमता को दर्शाती है - यह एक प्रकार का आउट-ऑफ-ऑर्डर निष्पादन है। मेमोरी रीऑर्डरिंग का उपयोग विभिन्न प्रकार की मेमोरी जैसे सीपीयू कैश # कैश प्रविष्टियों और मेमोरी बैंकों के बस-बैंडविड्थ का पूरी तरह से उपयोग करने के लिए किया जा सकता है।
अधिकांश आधुनिक यूनिप्रोसेसर प्रणाली पर मेमोरी ऑपरेशन प्रोग्राम कोड द्वारा निर्दिष्ट क्रम में निष्पादित नहीं होते हैं। एकल थ्रेडेड प्रोग्राम में सभी ऑपरेशन निर्दिष्ट क्रम में निष्पादित होते प्रतीत होते हैं, सभी आउट-ऑफ़-ऑर्डर निष्पादन प्रोग्रामर के लिए छिपे होते हैं - हालाँकि मल्टी-थ्रेडेड वातावरण में (या मेमोरी बसों के माध्यम से अन्य हार्डवेयर के साथ इंटरफेस करते समय) यह हो सकता है समस्या। समस्याओं से बचने के लिए, इन मामलों में स्मृति बाधा का उपयोग किया जा सकता है।
संकलन-समय स्मृति क्रम
अधिकांश प्रोग्रामिंग भाषाओं में निष्पादन के एक धागे की कुछ धारणा होती है जो एक निर्धारित क्रम में कथनों को निष्पादित करता है। पारंपरिक कंपाइलर उच्च-स्तरीय अभिव्यक्तियों को अंतर्निहित मशीन स्तर पर कार्यक्रम गणक के सापेक्ष निम्न-स्तरीय निर्देशों के अनुक्रम में अनुवाद करते हैं।
निष्पादन प्रभाव दो स्तरों पर दिखाई देते हैं: प्रोग्राम कोड के भीतर उच्च स्तर पर, और मशीन स्तर पर जैसा कि समवर्ती प्रोग्रामिंग में अन्य थ्रेड्स या प्रोसेसिंग तत्वों द्वारा देखा जाता है, या डिबगिंग के दौरान मशीन स्थिति तक पहुंच के साथ हार्डवेयर डिबगिंग सहायता का उपयोग करते समय ( इसके लिए कुछ समर्थन अक्सर निष्पादन कोर के अलावा कार्यात्मक रूप से स्वतंत्र सर्किटरी के रूप में सीधे सीपीयू या माइक्रोकंट्रोलर में बनाया जाता है जो तब भी काम करना जारी रखता है जब कोर स्वयं अपने निष्पादन स्थिति के स्थैतिक निरीक्षण के लिए रुका होता है)। संकलन-समय स्मृति क्रम स्वयं पूर्व से संबंधित है, और इन अन्य विचारों से संबंधित नहीं है।
कार्यक्रम क्रम के सामान्य मुद्दे
अभिव्यक्ति मूल्यांकन के कार्यक्रम-क्रम प्रभाव
संकलन के दौरान, हार्डवेयर निर्देश अक्सर उच्च-स्तरीय कोड में निर्दिष्ट की तुलना में अधिक बारीक विवरण पर उत्पन्न होते हैं। प्रक्रियात्मक प्रोग्रामिंग में प्राथमिक अवलोकनीय प्रभाव नामित चर के लिए एक नया मान निर्दिष्ट करना है।
योग = ए + बी + सी; प्रिंट(योग);
प्रिंट स्टेटमेंट उस स्टेटमेंट का अनुसरण करता है जो वेरिएबल योग को निर्दिष्ट करता है, और इस प्रकार जब प्रिंट स्टेटमेंट गणना किए गए वेरिएबल को संदर्भित करता है sum यह इस परिणाम को पूर्व निष्पादन अनुक्रम के अवलोकनीय प्रभाव के रूप में संदर्भित करता है। जैसा कि प्रोग्राम अनुक्रम के नियमों द्वारा परिभाषित किया गया है, जब print फ़ंक्शन कॉल संदर्भ sum, का मान है sum वेरिएबल के लिए सबसे हाल ही में निष्पादित असाइनमेंट होना चाहिए sum (इस मामले में ठीक पिछला बयान)।
मशीन स्तर पर, कुछ मशीनें एक ही निर्देश में तीन संख्याओं को एक साथ जोड़ सकती हैं, और इसलिए कंपाइलर को इस अभिव्यक्ति को दो अतिरिक्त कार्यों में अनुवाद करना होगा। यदि प्रोग्राम भाषा के शब्दार्थ कंपाइलर को बाएं से दाएं क्रम में अभिव्यक्ति का अनुवाद करने से रोकते हैं (उदाहरण के लिए), तो उत्पन्न कोड ऐसा दिखेगा जैसे प्रोग्रामर ने मूल प्रोग्राम में निम्नलिखित कथन लिखे थे:
योग = ए + बी; योग = योग + सी;
यदि कंपाइलर को जोड़ की सहयोगी संपत्ति का फायदा उठाने की अनुमति है, तो यह इसके बजाय उत्पन्न कर सकता है:
योग = बी + सी; योग = ए + योग;
यदि कंपाइलर को जोड़ की क्रमविनिमेय संपत्ति का फायदा उठाने की भी अनुमति है, तो यह इसके बजाय उत्पन्न कर सकता है:
योग = ए + सी; योग = योग + बी;
ध्यान दें कि अधिकांश प्रोग्रामिंग भाषाओं में पूर्णांक डेटा प्रकार केवल पूर्णांक अतिप्रवाह की अनुपस्थिति में गणित के पूर्णांकों के लिए बीजगणित का अनुसरण करता है और अधिकांश प्रोग्रामिंग भाषाओं में उपलब्ध फ़्लोटिंग पॉइंट डेटा प्रकार पर फ़्लोटिंग-पॉइंट अंकगणित गोलाई प्रभावों में क्रमविनिमेय नहीं है, जिससे प्रभाव पड़ता है गणना किए गए परिणाम के छोटे अंतरों में दिखाई देने वाली अभिव्यक्ति का क्रम (हालांकि छोटे प्रारंभिक अंतर लंबी गणना के दौरान मनमाने ढंग से बड़े अंतर में बदल सकते हैं)।
यदि प्रोग्रामर फ़्लोटिंग पॉइंट में पूर्णांक अतिप्रवाह या गोलाकार प्रभावों के बारे में चिंतित है, तो उसी प्रोग्राम को मूल उच्च स्तर पर निम्नानुसार कोडित किया जा सकता है:
योग = ए + बी; योग = योग + सी;
फ़ंक्शन कॉल से जुड़े प्रोग्राम-ऑर्डर प्रभाव
कई भाषाएँ कथन की सीमा को एक अनुक्रम बिंदु के रूप में मानती हैं, जिससे एक कथन के सभी प्रभावों को अगले कथन के निष्पादित होने से पहले पूरा करने के लिए बाध्य किया जाता है। यह संकलक को व्यक्त कथन क्रम के अनुरूप कोड उत्पन्न करने के लिए बाध्य करेगा। हालाँकि, कथन अक्सर अधिक जटिल होते हैं, और उनमें आंतरिक फ़ंक्शन कॉल शामिल हो सकते हैं।
योग = एफ(ए) + जी(बी) + एच(सी);
मशीन स्तर पर, किसी फ़ंक्शन को कॉल करने में आमतौर पर फ़ंक्शन कॉल के लिए एक स्टैक फ़्रेम स्थापित करना शामिल होता है, जिसमें मशीन मेमोरी में कई पढ़ना और लिखना शामिल होता है। अधिकांश संकलित भाषाओं में, कंपाइलर फ़ंक्शन कॉल को ऑर्डर करने के लिए स्वतंत्र है f, g, और h जैसा कि यह सुविधाजनक लगता है, जिसके परिणामस्वरूप प्रोग्राम मेमोरी ऑर्डर में बड़े पैमाने पर बदलाव होते हैं। शुद्ध कार्यात्मक प्रोग्रामिंग भाषा में, फ़ंक्शन कॉल को दृश्यमान प्रोग्राम स्थिति (इसके रिटर्न मान के अलावा) पर दुष्प्रभाव होने से प्रतिबंधित किया जाता है और फ़ंक्शन कॉल ऑर्डरिंग के कारण मशीन मेमोरी ऑर्डर में अंतर प्रोग्राम सेमेन्टिक्स के लिए अप्रासंगिक होगा। प्रक्रियात्मक भाषाओं में, बुलाए गए कार्यों के दुष्प्रभाव हो सकते हैं, जैसे इनपुट/आउटपुट|आई/ओ ऑपरेशन करना, या वैश्विक प्रोग्राम दायरे में एक चर को अपडेट करना, ये दोनों प्रोग्राम मॉडल के साथ दृश्यमान प्रभाव उत्पन्न करते हैं।
फिर, इन प्रभावों से चिंतित एक प्रोग्रामर मूल स्रोत कार्यक्रम को व्यक्त करने में अधिक पांडित्यपूर्ण हो सकता है:
योग = एफ(ए); योग = योग + जी(बी); योग = योग + एच(सी);
प्रोग्रामिंग भाषाओं में जहां कथन सीमा को अनुक्रम बिंदु के रूप में परिभाषित किया जाता है, फ़ंक्शन कॉल करता है f, g, और h अब उस सटीक क्रम में निष्पादित करना होगा।
स्मृति क्रम के विशिष्ट मुद्दे
सूचक अभिव्यक्तियों से जुड़े प्रोग्राम-ऑर्डर प्रभाव
अब C या C++ जैसी भाषा में, जो पॉइंटर (कंप्यूटर प्रोग्रामिंग) का समर्थन करती है, पॉइंटर इनडायरेक्शन के साथ व्यक्त किए गए समान सारांश पर विचार करें:
योग = *ए + *बी + *सी;
अभिव्यक्ति का मूल्यांकन *x डीरेफ़रेंस ऑपरेटर को एक पॉइंटर कहा जाता है और इसमें वर्तमान मान द्वारा निर्दिष्ट स्थान पर मेमोरी से पढ़ना शामिल होता है x. पॉइंटर से पढ़ने के प्रभाव आर्किटेक्चर के मेमोरी मॉडल (प्रोग्रामिंग) द्वारा निर्धारित होते हैं। मानक प्रोग्राम स्टोरेज से पढ़ते समय, मेमोरी रीड ऑपरेशन के क्रम के कारण कोई दुष्प्रभाव नहीं होते हैं। अंतः स्थापित प्रणाली प्रोग्रामिंग में, मेमोरी-मैप्ड I/O होना बहुत आम है जहां मेमोरी ट्रिगर I/O ऑपरेशंस को पढ़ता और लिखता है, या प्रोसेसर के ऑपरेशनल मोड में बदलाव करता है, जो अत्यधिक दृश्यमान दुष्प्रभाव होते हैं। उपरोक्त उदाहरण के लिए, अभी मान लें कि पॉइंटर्स इन दुष्प्रभावों के बिना, नियमित प्रोग्राम मेमोरी की ओर इशारा कर रहे हैं। कंपाइलर इन रीड्स को प्रोग्राम क्रम में पुन: व्यवस्थित करने के लिए स्वतंत्र है, जैसा कि वह उचित समझता है, और कोई प्रोग्राम-दृश्यमान दुष्प्रभाव नहीं होगा।
यदि निर्दिष्ट मान भी सूचक अप्रत्यक्ष हो तो क्या होगा?
*योग = *ए + *बी + *सी;
यहां भाषा की परिभाषा संकलक को इसे इस प्रकार अलग करने की अनुमति देने की संभावना नहीं है:
// जैसा कि संकलक द्वारा पुनः लिखा गया है // आम तौर पर वर्जित *योग = *ए + *बी; *योग = *योग + *सी;
इसे अधिकांश मामलों में कुशल नहीं माना जाएगा, और पॉइंटर राइट्स के दृश्यमान मशीन स्थिति पर संभावित दुष्प्रभाव होते हैं। चूंकि कंपाइलर ने इस विशेष विभाजन परिवर्तन की अनुमति 'नहीं' दी है, इसलिए केवल स्मृति स्थान पर लिखें sum मूल्य अभिव्यक्ति में पढ़े गए तीन सूचकों का तार्किक रूप से पालन करना चाहिए।
हालाँकि, मान लीजिए कि प्रोग्रामर पूर्णांक अतिप्रवाह के दृश्यमान शब्दार्थ के बारे में चिंतित है और कथन को प्रोग्राम स्तर पर इस प्रकार अलग करता है:
//जैसा कि सीधे प्रोग्रामर द्वारा लिखा गया है //अलियासिंग चिंताओं के साथ *योग = *ए + *बी; *योग = *योग + *सी;
पहला कथन दो मेमोरी रीड्स को एन्कोड करता है, जो पहले लिखने से पहले (किसी भी क्रम में) होना चाहिए *sum. दूसरा कथन दो मेमोरी रीड्स को एन्कोड करता है (किसी भी क्रम में) जो दूसरे अपडेट से पहले होना चाहिए *sum. यह दो अतिरिक्त परिचालनों के क्रम की गारंटी देता है, लेकिन संभावित रूप से एड्रेस अलियासिंग (कंप्यूटिंग) की एक नई समस्या पेश करता है: इनमें से कोई भी पॉइंटर संभावित रूप से उसी मेमोरी स्थान को संदर्भित कर सकता है।
उदाहरण के लिए, आइए इस उदाहरण में मान लें कि *c और *sum एक ही मेमोरी स्थान पर उपनाम दिया जाता है, और प्रोग्राम के दोनों संस्करणों को फिर से लिखा जाता है *sum दोनों के लिए खड़ा हूँ.
*योग = *ए + *बी + *योग;
यहां कोई समस्या नहीं है. जो हमने मूल रूप से लिखा था उसका मूल मूल्य *c को सौंपे जाने पर खो जाता है *sum, और इसका मूल मूल्य भी ऐसा ही है *sum लेकिन इसे पहले ही ओवरराइट कर दिया गया था और यह कोई विशेष चिंता का विषय नहीं है।
// *c और *sum उपनाम के साथ प्रोग्राम क्या बन जाता है *योग = *ए + *बी; *योग = *योग + *योग;
यहाँ का मूल मूल्य है *sum इसकी पहली पहुंच से पहले इसे अधिलेखित कर दिया जाता है, और इसके बजाय हमें इसका बीजगणितीय समतुल्य प्राप्त होता है:
// उपरोक्त उपनाम मामले के बीजगणितीय समकक्ष *योग = (*ए + *बी) + (*ए + *बी);
जो पूरी तरह से अलग मान निर्दिष्ट करता है *sum कथन पुनर्व्यवस्था के कारण.
संभावित अलियासिंग प्रभावों के कारण, दृश्यमान प्रोग्राम प्रभावों को जोखिम में डाले बिना सूचक अभिव्यक्तियों को पुनर्व्यवस्थित करना मुश्किल होता है। सामान्य स्थिति में, कोई उपनाम प्रभाव में नहीं हो सकता है, इसलिए कोड पहले की तरह सामान्य रूप से चलता हुआ प्रतीत होता है। लेकिन किनारे के मामले में जहां अलियासिंग मौजूद है, गंभीर प्रोग्राम त्रुटियां हो सकती हैं। यहां तक कि अगर ये किनारे के मामले सामान्य निष्पादन में पूरी तरह से अनुपस्थित हैं, तो यह एक दुर्भावनापूर्ण प्रतिद्वंद्वी के लिए एक इनपुट प्राप्त करने का द्वार खोलता है जहां एलियासिंग मौजूद है, जो संभावित रूप से कंप्यूटर सुरक्षा शोषण (कंप्यूटर सुरक्षा) का कारण बनता है।
पिछले प्रोग्राम का सुरक्षित पुनः क्रम इस प्रकार है:
// उपयुक्त प्रकार का एक अस्थायी स्थानीय चर 'temp' घोषित करें अस्थायी = *ए + *बी; *योग = तापमान + *सी;
अंत में अतिरिक्त फ़ंक्शन कॉल के साथ अप्रत्यक्ष मामले पर विचार करें:
*योग = एफ(*ए) + जी(*बी);
संकलक मूल्यांकन करना चुन सकता है *a और *b किसी भी फ़ंक्शन कॉल से पहले, यह मूल्यांकन को स्थगित कर सकता है *b फ़ंक्शन कॉल के बाद तक f या फिर इसके मूल्यांकन को टाला जा सकता है *a फ़ंक्शन कॉल के बाद तक g. यदि कार्य f और g कार्यक्रम के दृश्यमान दुष्प्रभावों से मुक्त हैं, सभी तीन विकल्प समान दृश्यमान कार्यक्रम प्रभावों के साथ एक कार्यक्रम का निर्माण करेंगे। यदि का कार्यान्वयन f या g इसमें पॉइंटर्स के साथ अलियासिंग के अधीन किसी भी पॉइंटर राइट का साइड-इफ़ेक्ट शामिल होता है a या b, तीन विकल्प अलग-अलग दृश्य कार्यक्रम प्रभाव उत्पन्न करने के लिए उत्तरदायी हैं।
भाषा विनिर्देश में मेमोरी क्रम
सामान्य तौर पर, संकलित भाषाएँ अपने विनिर्देशन में इतनी विस्तृत नहीं होती हैं कि संकलक संकलन समय पर औपचारिक रूप से यह निर्धारित कर सके कि कौन से सूचक संभावित रूप से उपनामित हैं और कौन से नहीं। कंपाइलर के लिए कार्रवाई का सबसे सुरक्षित तरीका यह मान लेना है कि सभी पॉइंटर्स हर समय संभावित रूप से अलियास किए गए हैं। रूढ़िवादी निराशावाद का यह स्तर आशावादी धारणा की तुलना में भयानक प्रदर्शन उत्पन्न करता है कि कोई उपनाम मौजूद नहीं है।
परिणामस्वरूप, कई उच्च-स्तरीय संकलित भाषाएँ, जैसे कि C/C++, जटिल और परिष्कृत अर्थ संबंधी विशिष्टताओं के लिए विकसित हुई हैं, जहाँ संकलक को उच्चतम संभव प्रदर्शन की खोज में कोड पुन: व्यवस्थित करने में आशावादी धारणाएँ बनाने की अनुमति है, और कहाँ सिमेंटिक खतरों से बचने के लिए कंपाइलर को कोड रीऑर्डरिंग में निराशावादी धारणाएं बनाने की आवश्यकता होती है।
आधुनिक प्रक्रियात्मक भाषा में साइड इफेक्ट्स के अब तक के सबसे बड़े वर्ग में मेमोरी राइट ऑपरेशन शामिल हैं, इसलिए मेमोरी ऑर्डरिंग के नियम प्रोग्राम ऑर्डर सिमेंटिक्स की परिभाषा में एक प्रमुख घटक हैं। ऊपर दिए गए फ़ंक्शन कॉलों का पुन: क्रमित करना एक अलग विचार प्रतीत हो सकता है, लेकिन यह आम तौर पर अभिव्यक्ति में मेमोरी ऑपरेशंस के साथ इंटरैक्ट करने वाले कॉल किए गए फ़ंक्शन के आंतरिक मेमोरी प्रभावों के बारे में चिंताओं में बदल जाता है जो फ़ंक्शन कॉल उत्पन्न करता है।
अतिरिक्त कठिनाइयाँ और जटिलताएँ
==== यथा-यदि ==== के अंतर्गत अनुकूलन
आधुनिक कंपाइलर कभी-कभी इसे एक ऐसे नियम के माध्यम से एक कदम आगे ले जाते हैं, जिसमें दृश्य कार्यक्रम शब्दार्थ परिणामों पर कोई प्रभाव नहीं पड़ने पर किसी भी पुन: क्रम की अनुमति दी जाती है (यहां तक कि बयानों में भी)। इस नियम के तहत, अनुवादित कोड में संचालन का क्रम निर्दिष्ट प्रोग्राम क्रम से काफी भिन्न हो सकता है। यदि कंपाइलर को अलग-अलग सूचक अभिव्यक्तियों के बारे में आशावादी धारणाएं बनाने की अनुमति दी जाती है, जिसमें कोई उपनाम ओवरलैप नहीं होता है, ऐसे मामले में जहां ऐसा उपनाम वास्तव में मौजूद होता है (इसे आम तौर पर अपरिभाषित व्यवहार प्रदर्शित करने वाले एक बीमार कार्यक्रम के रूप में वर्गीकृत किया जाएगा), एक आक्रामक कोड के प्रतिकूल परिणाम- कोड निष्पादन या प्रत्यक्ष कोड निरीक्षण से पहले अनुकूलन परिवर्तन का अनुमान लगाना असंभव है। अपरिभाषित व्यवहार के दायरे में लगभग असीमित अभिव्यक्तियाँ हैं।
यह प्रोग्रामर की ज़िम्मेदारी है कि वह गलत तरीके से बनाए गए प्रोग्राम लिखने से बचने के लिए भाषा विनिर्देश से परामर्श ले, जहां किसी भी कानूनी कंपाइलर अनुकूलन के परिणामस्वरूप शब्दार्थ संभावित रूप से बदल जाते हैं। फोरट्रान परंपरागत रूप से प्रोग्रामर पर इन मुद्दों के बारे में जागरूक होने का एक बड़ा बोझ डालता है, सिस्टम प्रोग्रामिंग भाषाएं सी और सी++ भी पीछे नहीं हैं।
कुछ उच्च-स्तरीय भाषाएँ पॉइंटर निर्माण को पूरी तरह से समाप्त कर देती हैं, क्योंकि पेशेवर प्रोग्रामर के बीच भी सतर्कता और विस्तार पर ध्यान देने के इस स्तर को विश्वसनीय रूप से बनाए रखने के लिए बहुत अधिक माना जाता है।
मेमोरी ऑर्डर सिमेंटिक्स की पूरी समझ को पेशेवर सिस्टम प्रोग्रामर की उप-जनसंख्या के बीच भी एक रहस्यमय विशेषज्ञता माना जाता है, जो आमतौर पर इस विषय क्षेत्र में सबसे अच्छी जानकारी रखते हैं। अधिकांश प्रोग्रामर अपनी प्रोग्रामिंग विशेषज्ञता के सामान्य क्षेत्र के भीतर इन मुद्दों की पर्याप्त कामकाजी समझ के लिए समझौता करते हैं। मेमोरी ऑर्डर सिमेंटिक्स में विशेषज्ञता के चरम छोर पर प्रोग्रामर हैं जो समवर्ती कंप्यूटिंग मॉडल के समर्थन में सॉफ्टवेयर ढांचा लिखते हैं।
स्थानीय चर का उपनाम
ध्यान दें कि स्थानीय चर को अलियासिंग से मुक्त नहीं माना जा सकता है यदि ऐसे चर का सूचक जंगल में भाग जाता है:
योग = f(&a) + g(a);
यह बताने वाला नहीं है कि कार्य क्या है f हो सकता है कि उसने आपूर्ति किए गए पॉइंटर के साथ ऐसा किया हो a, जिसमें वैश्विक स्थिति में एक प्रति छोड़ना शामिल है जो कार्य करता है g बाद में पहुँचता है। सबसे सरल मामले में, f वेरिएबल के लिए एक नया मान लिखता है a, निष्पादन के क्रम में इस अभिव्यक्ति को खराब परिभाषित कर रहा है। f इसके सूचक तर्क की घोषणा में कॉन्स्ट (कंप्यूटर प्रोग्रामिंग) लागू करके, अभिव्यक्ति को अच्छी तरह से परिभाषित करके ऐसा करने से स्पष्ट रूप से रोका जा सकता है। इस प्रकार C/C++ की आधुनिक संस्कृति सभी व्यवहार्य मामलों में तर्क घोषणाओं को कार्यान्वित करने के लिए कॉन्स्ट क्वालिफायर की आपूर्ति करने के प्रति कुछ हद तक जुनूनी हो गई है।
C और C++ आंतरिक की अनुमति देते हैं f रूपांतरण टाइप करने के लिए स्थिरता विशेषता को एक खतरनाक समीचीन के रूप में दूर किया जाता है। अगर f यह इस तरह से करता है कि उपरोक्त अभिव्यक्ति को तोड़ सकता है, इसे पहले स्थान पर सूचक तर्क प्रकार को कॉन्स्ट के रूप में घोषित नहीं करना चाहिए।
अन्य उच्च-स्तरीय भाषाएँ ऐसी घोषणा विशेषता की ओर झुकती हैं जो भाषा के भीतर प्रदान की गई इस गारंटी का उल्लंघन करने के लिए कोई लूप-होल के साथ एक मजबूत गारंटी की तरह होती है; यदि आपका एप्लिकेशन किसी भिन्न प्रोग्रामिंग भाषा में लिखी लाइब्रेरी को लिंक करता है (हालांकि इसे बेहद खराब डिज़ाइन माना जाता है) तो इस भाषा गारंटी पर सभी दांव छूट जाएंगे।
संकलन-समय स्मृति बाधा कार्यान्वयन
ये बाधाएँ कंपाइलर को संकलन समय के दौरान निर्देशों को पुन: व्यवस्थित करने से रोकती हैं - वे रनटाइम के दौरान सीपीयू द्वारा पुन: क्रमित करने को नहीं रोकते हैं।
- इनमें से कोई भी जीएनयू इनलाइन असेंबलर स्टेटमेंट जीएनयू कंपाइलर संग्रह कंपाइलर को इसके आसपास कमांड को पढ़ने और लिखने के लिए पुन: व्यवस्थित करने से रोकता है:[1]
एएसएम अस्थिर (::: मेमोरी);
__asm__ __volatile__ ( ::: मेमोरी );
- यह C11/C++11 फ़ंक्शन कंपाइलर को इसके चारों ओर कमांड को पढ़ने और लिखने के लिए पुन: व्यवस्थित करने से रोकता है:[2]
परमाणु_सिग्नल_बाड़(मेमोरी_ऑर्डर_एसीक्यू_रेल);
__मेमोरी_बैरियर()
- माइक्रोसॉफ्ट विजुअल सी++ कंपाइलर (एमएसवीसी) केवल x86/x64 के लिए कुछ आंतरिक चीजों का समर्थन करता है (ये सभी अप्रचलित हैं):[5]
_रीडबैरियर() _राइटबैरियर() _रीडराइटबैरियर()
संयुक्त बाधाएँ
कई प्रोग्रामिंग भाषाओं में विभिन्न प्रकार की बाधाओं को अन्य परिचालनों (जैसे लोड, स्टोर, परमाणु वृद्धि, परमाणु तुलना और स्वैप) के साथ जोड़ा जा सकता है, इसलिए इसके पहले या बाद में (या दोनों) किसी अतिरिक्त मेमोरी बाधा की आवश्यकता नहीं होती है। लक्षित सीपीयू आर्किटेक्चर के आधार पर ये भाषा निर्माण हार्डवेयर मेमोरी ऑर्डरिंग गारंटी के आधार पर या तो विशेष निर्देशों, एकाधिक निर्देशों (यानी बाधा और लोड), या सामान्य निर्देश में अनुवाद करेंगे।
रनटाइम मेमोरी ऑर्डरिंग
सममित मल्टीप्रोसेसिंग (एसएमपी) माइक्रोप्रोसेसर सिस्टम में
सममित मल्टीप्रोसेसिंग सिस्टम के लिए कई मेमोरी-संगति मॉडल हैं:
- अनुक्रमिक संगति (सभी पढ़ा गया और सभी लिखा गया क्रम में है)
- आरामदायक स्थिरता (कुछ प्रकार के पुनर्क्रमण की अनुमति है)
- लोड के बाद लोड को फिर से व्यवस्थित किया जा सकता है (कैश सुसंगतता के बेहतर काम के लिए, बेहतर स्केलिंग के लिए)
- स्टोर के बाद लोड को फिर से व्यवस्थित किया जा सकता है
- स्टोर्स को स्टोर्स के बाद पुनः व्यवस्थित किया जा सकता है
- लोड के बाद स्टोर को फिर से व्यवस्थित किया जा सकता है
- कमजोर स्थिरता (पढ़ने और लिखने को मनमाने ढंग से पुन: व्यवस्थित किया जाता है, केवल स्पष्ट स्मृति बाधाओं द्वारा सीमित)
कुछ सीपीयू पर
- परमाणु संचालन को भार और भंडार के साथ पुन: व्यवस्थित किया जा सकता है।[6]
- असंगत निर्देश कैश पाइपलाइन हो सकती है, जो स्व-संशोधित कोड को विशेष निर्देश कैश फ्लश/रीलोड निर्देशों के बिना निष्पादित होने से रोकती है।
- आश्रित भार को पुन: व्यवस्थित किया जा सकता है (यह अल्फा के लिए अद्वितीय है)। यदि प्रोसेसर पहले कुछ डेटा के लिए एक पॉइंटर लाता है और फिर डेटा, तो यह स्वयं डेटा नहीं ला सकता है बल्कि पुराने डेटा का उपयोग कर सकता है जिसे उसने पहले ही कैश कर लिया है और अभी तक अमान्य नहीं किया है। इस छूट की अनुमति देने से कैश हार्डवेयर सरल और तेज़ हो जाता है लेकिन पाठकों और लेखकों के लिए मेमोरी बाधाओं की आवश्यकता होती है।[7] अल्फा हार्डवेयर पर (मल्टीप्रोसेसर अल्फ़ा 21264 सिस्टम की तरह) अन्य प्रोसेसर को भेजे गए कैश लाइन अमान्यकरण को डिफ़ॉल्ट रूप से आलसी तरीके से संसाधित किया जाता है, जब तक कि स्पष्ट रूप से निर्भर लोड के बीच संसाधित होने का अनुरोध नहीं किया जाता है। अल्फा आर्किटेक्चर विनिर्देश अन्य प्रकार के आश्रित भारों को पुन: व्यवस्थित करने की भी अनुमति देता है, उदाहरण के लिए वास्तविक सूचक को डीरेफ़रेंस करने के बारे में जानने से पहले सट्टा डेटा रीड्स का उपयोग करना।
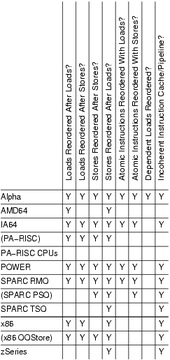
| Type | Alpha | ARMv7 | MIPS | RISC-V | PA-RISC | POWER | SPARC | x86 [lower-alpha 1] | AMD64 | IA-64 | z/Architecture | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WMO | TSO | RMO | PSO | TSO | ||||||||||
| Loads can be reordered after loads | Y | Y | depend on implementation |
Y | Y | Y | Y | Y | ||||||
| Loads can be reordered after stores | Y | Y | Y | Y | Y | Y | Y | |||||||
| Stores can be reordered after stores | Y | Y | Y | Y | Y | Y | Y | Y | ||||||
| Stores can be reordered after loads | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | |
| Atomic can be reordered with loads | Y | Y | Y | Y | Y | Y | ||||||||
| Atomic can be reordered with stores | Y | Y | Y | Y | Y | Y | Y | |||||||
| Dependent loads can be reordered | Y | |||||||||||||
| Incoherent instruction cache/pipeline | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | ||||
- आरआईएससी-वी मेमोरी ऑर्डरिंग मॉडल
-
- WMO
- कमजोर मेमोरी ऑर्डर (डिफ़ॉल्ट)
- TSO
- कुल स्टोर ऑर्डर (केवल Ztso एक्सटेंशन के साथ समर्थित)
- SPARC मेमोरी ऑर्डरिंग मोड
-
- टीएसओ
- कुल स्टोर ऑर्डर (डिफ़ॉल्ट)
- आरएमओ
- रिलैक्स्ड-मेमोरी ऑर्डर (हालिया सीपीयू पर समर्थित नहीं)
- पीएसओ
- आंशिक स्टोर ऑर्डर (हालिया सीपीयू पर समर्थित नहीं)
हार्डवेयर मेमोरी बैरियर कार्यान्वयन
एसएमपी समर्थन वाले कई आर्किटेक्चर में रन टाइम (प्रोग्राम जीवनचक्र चरण) के दौरान पढ़ने और लिखने को फ्लश करने के लिए विशेष हार्डवेयर निर्देश होते हैं।
एलफेंस (एएसएम), शून्य _एमएम_एलफेंस(शून्य) sfence (asm), void _mm_sfence(void)[11]
mfence (asm), void _mm_mfence(void)[12]
सिंक (एएसएम)
सिंक (एएसएम)[13][14]
एमएफ (एएसएम)
डीसीएस (एएसएम)
डीएमबी (एएसएम)
डीएसबी (एएसएम) आईएसबी (एएसएम)
हार्डवेयर मेमोरी बाधाओं के लिए कंपाइलर समर्थन
कुछ कंपाइलर आंतरिक फ़ंक्शन का समर्थन करते हैं जो हार्डवेयर मेमोरी बैरियर निर्देशों का उत्सर्जन करते हैं:
- जीएनयू कंपाइलर संग्रह,[16] संस्करण 4.4.0 और बाद का संस्करण,[17] है
__sync_synchronize. - चूंकि C11 और C++11 an
atomic_thread_fence()कमांड जोड़ा गया. - Microsoft विज़ुअल C++ कंपाइलर है
MemoryBarrier()विंडोज़ एपीआई हेडर में मैक्रो (पदावनत)।[18][5]*सन स्टूडियो कंपाइलर सुइट[19] है__machine_r_barrier,__machine_w_barrierऔर__machine_rw_barrier.
यह भी देखें
- मेमोरी मॉडल (प्रोग्रामिंग)
संदर्भ
- ↑ GCC compiler-gcc.h Archived 2011-07-24 at the Wayback Machine
- ↑ "std::atomic_signal_fence". ccpreference.
- ↑ ECC compiler-intel.h Archived 2011-07-24 at the Wayback Machine
- ↑ Intel(R) C++ Compiler Intrinsics Reference[dead link]
Creates a barrier across which the compiler will not schedule any data access instruction. The compiler may allocate local data in registers across a memory barrier, but not global data.
- ↑ 5.0 5.1 "_रीडराइटबैरियर". Microsoft Learn.
- ↑ Victor Alessandrini, 2015. Shared Memory Application Programming: Concepts and Strategies in Multicore Application Programming. Elsevier Science. p. 176. ISBN 978-0-12-803820-8.
- ↑ Reordering on an Alpha processor by Kourosh Gharachorloo
- ↑ Memory Ordering in Modern Microprocessors by Paul McKenney
- ↑ Memory Barriers: a Hardware View for Software Hackers, Figure 5 on Page 16
- ↑ Table 1. Summary of Memory Ordering, from "Memory Ordering in Modern Microprocessors, Part I"
- ↑ SFENCE — Store Fence
- ↑ MFENCE — Memory Fence
- ↑ "MIPS® Coherence Protocol Specification, Revision 01.01" (PDF). p. 26. Retrieved 2023-12-15.
- ↑ "MIPS instruction set R5" (PDF). p. 59-60. Retrieved 2023-12-15.
- ↑ Data Memory Barrier, Data Synchronization Barrier, and Instruction Synchronization Barrier.
- ↑ Atomic Builtins
- ↑ "36793 – x86-64 does not get __sync_synchronize right".
- ↑ "MemoryBarrier function (winnt.h) - Win32 apps". Microsoft Learn.
- ↑ Handling Memory Ordering in Multithreaded Applications with Oracle Solaris Studio 12 Update 2: Part 2, Memory Barriers and Memory Fence [1]
{kind=link}
अग्रिम पठन
- Computer Architecture — A quantitative approach. 4th edition. J Hennessy, D Patterson, 2007. Chapter 4.6
- Sarita V. Adve, Kourosh Gharachorloo, Shared Memory Consistency Models: A Tutorial
- Intel 64 Architecture Memory Ordering White Paper
- Memory ordering in Modern Microprocessors part 1
- Memory ordering in Modern Microprocessors part 2
- IA (Intel Architecture) Memory Ordering on YouTube - Google Tech Talk